全球首个运行在安卓手机上的Stable Diffusion诞生,AIGC应用由云端服务器转向【边缘端AI芯片】的时代开启 关注我,持续带你们一起挖掘数字经济中人工智能赛道最新的技术!!!我这篇文章,是全网第一篇介绍AIGC模型推理降本最佳解决... |
您所在的位置:网站首页 › 安卓 开启ssh › 全球首个运行在安卓手机上的Stable Diffusion诞生,AIGC应用由云端服务器转向【边缘端AI芯片】的时代开启 关注我,持续带你们一起挖掘数字经济中人工智能赛道最新的技术!!!我这篇文章,是全网第一篇介绍AIGC模型推理降本最佳解决... |
全球首个运行在安卓手机上的Stable Diffusion诞生,AIGC应用由云端服务器转向【边缘端AI芯片】的时代开启 关注我,持续带你们一起挖掘数字经济中人工智能赛道最新的技术!!!我这篇文章,是全网第一篇介绍AIGC模型推理降本最佳解决...
|
来源:雪球App,作者: 爱者之贻bit,(https://xueqiu.com/8736499677/243563074) 关注我,持续带你们一起挖掘数字经济中人工智能赛道最新的技术!!!我这篇文章,是全网第一篇介绍AIGC模型推理降本最佳解决方案,由云端服务器转向边缘端人工智能芯片,欢迎大家点赞,转发和交流!!!================================================================= 之前大家可能都是炒作的AIGC大模型,训练和推理都需要部署在云端服务器上,需要大量的云端人工智能芯片$浪潮信息(SZ000977)$ , 而我后来也强调,人工智能芯片不止有云端训练芯片,也有边缘端推理芯片。通过AIGC应用由云端服务器转向【边缘端人工智能芯片】的方式,直接将公司自己的成本,转向用户自己手机等硬件的成本,这是非常好的解决方案! 这不,AIGC应用由云端服务器转向【边缘端人工智能芯片】的标志性事件,就在前两天发生了,也就是【全球首个运行在Android手机上的Stable Diffusion终端侧演示】,是$高通(QCOM)$ 公司成功地将AIGC中 AI作画的模型,部署到第二代骁龙8移动平台的手机上运行。 这意味着,以后的AIGC的模型,你只要拥有一部性能不低于小米13的安卓手机,就能够进行AI内容的创作,格局和空间直接打开? =================================================================
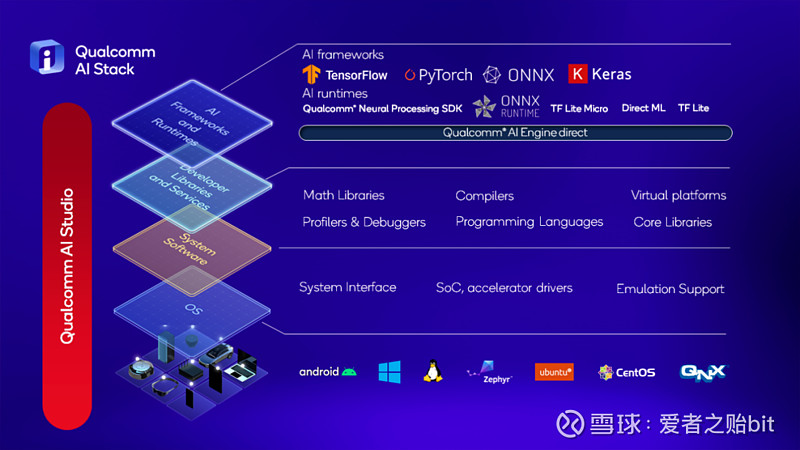
流行的基础模型Stable Diffusion是一个非常出色的从文本到图像的生成式AI模型,能够基于任何文本输入,在数十秒内创作出逼真图像。Stable Diffusion的参数超过10亿,迄今为止主要限于在云端运行。对此,高通技术公司工程技术副总裁侯纪磊和高通技术公司产品管理高级副总裁Ziad Asghar联合撰文,介绍高通AI Research如何利用高通AI软件栈(Qualcomm AI Stack)执行全栈AI优化,首次在Android智能手机上部署Stable Diffusion。
高通AI Research不仅在开展全新AI研究工作,也率先在商用终端上展示概念验证,为在现实世界中的技术规模化应用铺平道路。高通全栈AI研究指跨应用、神经网络模型、算法、软件和硬件进行优化,并在公司内进行跨部门合作。针对Stable Diffusion,侯纪磊和Ziad Asghar团队从Hugging Face的FP32 1-5版本开源模型入手,通过量化、编译和硬件加速进行优化,使其能在搭载第二代骁龙8移动平台的手机上运行。
为了把模型从FP32压缩为INT8,该团队使用了高通AI模型增效工具包(AIMET)的训练后量化。这是基于高通AI Research创造的技术所开发的工具,目前已经集成入新发布的Qualcomm AI Studio中。通过让模型在高通专用AI硬件上高效运行,并降低内存带宽消耗,量化不仅能够提高性能,还可以降低功耗。自适应舍入(AdaRound)等先进的高通AIMET量化技术能够在更低精度水平保持模型准确性,无需进行重新训练。这些技术能够应用于构成Stable Diffusion的所有组件模型,即基于Transformer的文本编码器、VAE解码器和UNet。这对于让模型适合于在终端上运行至关重要。
对于编译,该团队利用高通AI引擎Direct框架将神经网络映射到能够在目标硬件上高效运行的程序中。高通AI引擎Direct框架基于高通Hexagon处理器的硬件架构和内存层级进行序列运算,从而提升性能并最小化内存溢出。部分上述增强特性是AI优化研究人员与编译器工程团队共同合作的成果,以此来提升AI推理时的内存管理。高通AI引擎中所做的整体优化能够显著降低runtime的时延和功耗,而这一亟需的趋势也同样存在于Stable Diffusion上。 凭借紧密的软硬件协同设计,集成Hexagon处理器的高通AI引擎能够释放行业领先的边缘侧AI性能。支持微切片推理的最新第二代骁龙8移动平台有能力高效运行像Stable Diffusion这样的大模型,并且下一代骁龙预计还将带来更多提升。此外,由于构成Stable Diffusion的所有组件模型都采用了多头注意力机制,为加速推理而面向transformer模型(如MobileBERT)所做的技术增强发挥了关键作用。 这一全栈优化最终让Stable Diffusion能够在智能手机上运行,在15秒内执行20步推理,生成一张512x512像素的图像。这是在智能手机上最快的推理速度,能媲美云端时延,且用户文本输入完全不受限制。
(上图为Stable Diffusion利用文本提示:“野外河谷和山脉间的日式花园,高细节,数字插图,ArtStation,概念艺术,磨砂,锐聚焦,插图,戏剧性的,落日,炉石,artgerm、greg rutkowski和lphonse mucha的艺术作品”生成的图像。) 边缘侧AI的时代已经到来 随着AI云端大模型开始转向在边缘终端上运行,高通打造智能网联边缘的愿景正在加速实现,几年前还被认为不可能的事情正在成为可能。这很有吸引力,因为通过边缘AI进行终端侧处理具有诸多优势,包括可靠性、时延、隐私、网络带宽使用效率和整体成本。 尽管Stable Diffusion模型看起来过于庞大,但它编码了大量语言和视觉相关知识,几乎可以生成任何能想象到的图片。此外,作为一款基础模型,Stable Diffusion能做的远不止根据文字提示生成图像。基于Stable Diffusion的应用正在不断增加,例如图像编辑、图像修复、风格转换和超分辨率等,将带来切实的影响。能够完全在终端上运行模型而无需连接互联网,将带来无限的可能性。 扩展边缘侧AI 在智能手机上运行Stable Diffusion只是开始。让这一目标得以实现的所有全栈研究和优化都将融入高通AI软件栈。凭借高通的统一技术路线图,高通AI Research能够利用单一AI软件栈并进行扩展,以适用于不同的终端和不同的模型。 这意味着为了让Stable Diffusion在手机上高效运行所做的优化也可用于高通赋能的其他平台,比如笔记本电脑、XR头显和几乎任何其它终端。在云端运行所有AI处理工作成本高昂,因此高效的边缘侧AI处理非常重要。由于输入文本和生成图像始终无需离开终端,边缘侧AI处理能在运行Stable Diffusion(和其它生成式AI模型)时确保用户隐私,这对于使用消费级和企业级应用都有巨大的好处。全新AI软件栈优化还将有助于减少未来在边缘侧运行的下一代基础模型产品的上市时间。基于上述研究和优化,高通AI Research能够实现跨终端和基础模型进行扩展,让边缘侧AI真正无处不在。 高通AI Research在基础研究领域实现突破,并跨终端和行业进行扩展,以赋能智能网联边缘。高通AI Research与公司所有团队通力合作,将最新AI发展成果和技术集成到高通产品之中,让实验室研究所实现的AI进步能够更快交付,丰富人们的生活。 ================================================================= Top 15国产边缘/端侧AI芯片AspenCore分析师团队从15家国产AI芯片厂商中挑选出15个国产边缘/端侧AI芯片,请大家在文末通过“微信投票”评选出最喜欢的国产边缘AI芯片。这些公司包括:瑞芯微、全志、清微智能、酷芯微、亿智电子、时识科技、九天睿芯、杭州国芯、知存科技、爱芯元智、时擎科技、启英泰伦、深聪智能、灵汐科技、闪易半导体。 ================================================================= 推荐标的:$芯原股份-U(SH688521)$ , 全志科技, 瑞芯微 全志科技: 全志科技2月7日在投资者互动平台表示,公司芯片产品已经广泛应用在智能图像、智能语音交互等人工智能应用场景。全志科技以客户为中心,凝聚卓越团队,坚持核心技术长期投入,在超高清视频编解码、高性能CPU/GPU/AI多核整合、先进工艺的高集成度、超低功耗、全栈集成平台等方面提供具有市场突出竞争力的系统解决方案和贴心服务,产品广泛适用于工业控制、智能家电、智能硬件、平板电脑、汽车电子、机器人、虚拟现实、网络机顶盒以及电源模拟器件、无线通信模组、智能物联网等多个产品领域。 瑞芯微: 瑞芯微Rockchip深耕AI市场,RK3399Pro和RK1808两颗人工智能旗舰芯片在智能家居、智能安防、视觉、手势识别、智能语音等领域得到广泛应用。其中,RK3399Pro内置性能高达3.0Tops,融合了Rockchip在机器视觉、语音处理、深度学习等领域多年经验打造的NPU,让典型深度神经网络Inception V3、ResNet34、VGG16等模型在其上的运行效果表现惊人,性能大幅提升。RK3399Pro是采用CPU+GPU+NPU硬件结构设计的AI芯片。 芯原股份:芯原股份董秘:尊敬的投资者您好,在AIoT领域,芯原用于人工智能的神经网络处理器IP(NPU)业界领先,已被50余家客户用于其100余款人工智能芯片中。芯原的神经网络处理器技术是基于GPU架构体系进行优化,利用其可编程、可扩展及并行处理能力,为各类主流人工智能算法提供硬件加速的微处理器技术,在单位功耗下的卷积计算能力突出。具体来看,芯原神经网络处理器技术包括自主可控的卷积神经网络加速、可编程的浮点运算加速、指令集和可编程的浮点运算专用编译器、优化器等工具设计;支持国际标准OpenVX1.2和OpenCL1.2EP/FP;支持最大32位浮点精度数据处理和张量处理的硬件加速;支持0.5TOPs到12.5TOPs性能的单卷积运算核的可扩展架构设计,多卷积运算核扩展后,NPUIP的运算能力可以达到50-200TOPs;同时,具有自主可控的指令集及专用编译器。感谢您的关注。 |





【本文地址】